NGINX – Optimising Redirects
We’re a big user of NGINX as you can probably imagine. It’s been fascinating to see it’s growth over the last 10 years and we love it’s quick adoption of new standards.
Optimisations are always important, especially at scale; we’re always looking for the cleanest way to do things and redirects are definitely one of the easiest and quickest wins.
Redirects are used when you want to send users to a different URL based on the requested page. Some popular reasons to do this are:
- Redirect users from a short memorable URI to a corresponding page
- Keep old URLs working after migrating from one bit of software to another
- Redirect discontinued product pages (returning 404s) to the most closely related page
Redirects can typically be done in using rewrite or return with the addition of map for large arrays of redirects. Lets look at the differences….
Using ‘rewrite’ for redirects
Rewrite isn’t all bad, it’s very powerful but with that comes a large CPU overhead as it uses regex by default.
Consider the following rule to redirect browsers accessing an image to a separate subdomain; perhaps a CDN…
rewrite ^/images/(*.jpg)$ http://static.example.com/$1 permanent;
Using ‘return’ for redirects
A redirect is as simple as returning a HTTP status code so why not do just that with the return option.
If you have to redirect an entire site to a new URL then it can be simply done with…
server { server_name oldsite.example.com; return 301 $scheme://newsite.example.com$request_uri; } server { server_name newsite.example.com; # [...] }
… remember that http and https configs can easily be separated to allow the http site to only forward on requests ensuring that it’s impossible for anyone to access your site insecurely…
server { listen 80; server_name www.example.com; return 301 https://www.example.com$request_uri; } server { listen 443; server_name www.example.com; # [...] }
Using ‘map’ for redirects
If you’ve only got a handful of redirects then using rewrite to do this isn’t a big deal. Once you’re talking about hundreds or thousands of redirects it’s worth looking to use a map.
Here’s an example configuration using a map and return directive to set-up two redirects.
Depending on how many URLs you’re redirecting you’ll need a different value for map_hash_bucket_size. I’d stick with powers of 2, a config test (nginx -t) will warn you if your value is too small.
$uri is an NGINX variable.
$new_uri is the new variable that we’re creating, if you’ve got multiple sites you’ll need to use different variable names.
map_hash_bucket_size 128;
map $uri $new_uri {
/test-to-rewrite /test-rewritten;
/test2-to-rewrite /test2-rewritten;
}
server {
server_name example.com;
if ($new_uri) {
return 301 $new_uri;
}
#...
}
For reference, here’s the equivalent syntax using rewrite.
server {
server_name example.com;
rewrite ^/test-to-rewrite$ /test-rewritten permanent;
rewrite ^/test2-to-rewrite$ /test2-rewritten permanent;
#...
}
Testing map performance
Before testing this my expectation was that there would be a cross over point after which using a map was beneficial. What I found was that a map is suitable for any number of redirects but it’s not until you have a large number that it’s essential.
Test conditions
- Ubuntu 18.04 on a AWS c5.large
- nginx v1.18.0
- Used ApacheBench to make 10k local requests with 500 concurrent connections
I ran each test 3 times and used the average in the numbers below. I was measuring:
- Time taken to complete all of the requests
- Memory usage with NGINX stopped, running and running after the test
I’m happy this can show the relationship between the number of redirects and the performance differences between a map and rewrite. Though it won’t represent your exact set-up.
Single redirect
The first thing I tested using both the rewrite and map configuration was a single redirect.
The time to complete these requests was comparable. Both round to 0.42s with the map being a few hundredths of a second slower. I believe this is within the errors of my testing. The memory usage of running NGINX was too close to separate, fluctuating between 3-6M.
Large (83k) redirects
After that I tested what I’d consider the other extreme. I pulled 83k lines out of the dictionary file and set-up redirects for them. I ran the test against multiple different words. This shows how the number of preceding redirects affects the time to complete the requests.
- Abdomen – which appears early in my redirects had comparable times (the average over the 3 test runs is actually identical)
- Absentee – the 250th redirect took 0.66s with rewrite rules and 0.42s with the map
- Animated – the 2500th redirect took 4.43s with rewrite rules and 0.42s with the map
- Evangelising – the 25000th redirect took 27.86s with rewrite rules and 0.42s with the map
- Zing – which appears late in my redirects took 57.54s with rewrite rules and 0.42s with the map
- The 404 page I was testing – this represents load times of any small static page below the redirects in the config, it took 56.89s with rewrite rules and 0.43s with the map
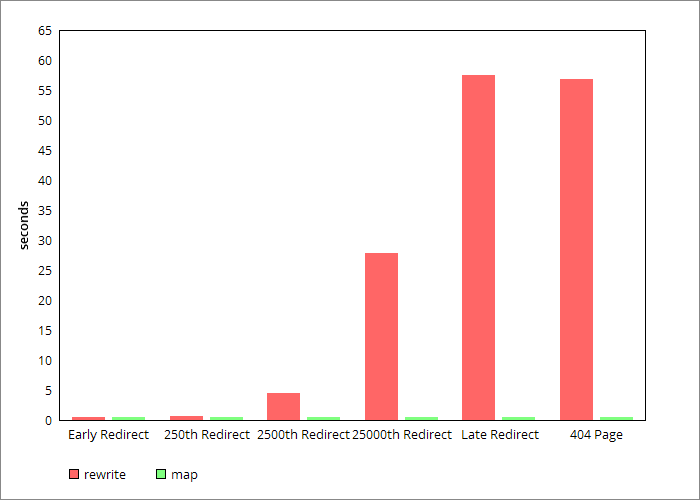
The time to process each different redirect was effectively constant when using a map. Using rewrite the time to process a redirect is proportional to the number of rewrite rules before it.
Memory usage was also noticeably different. I found that the increase due to running NGINX was ~16M for the map and ~66M for the rewrites. After the test had run this increased by a few megabytes to ~19M and ~68M.
250 redirects
I wanted to check if the sheer number of rewrites was slowing things down. I cut the config down to just the first 250 redirects. This significantly reduced memory usage. The time taken for requests to the Absentee redirect was negligibly different from when there were 83k redirects.
Fewer requests
I ran an extra test with 100 requests (rather than 10k) and 5 concurrent connections (rather than 500). This is also a closer approximation to a single user accessing a webpage. The time taken to access the Zing redirect was 0.55s (rather than 57.65s). I’m happy that this shows the time for a single request is effectively constant.
Conclusion
For a large number of redirects a map is both faster and more memory efficient. For a small number of redirects either rewrite or using a map is acceptable. Since there’s no discernible disadvantage to a map and you may need to add more redirects in the future I’d use a map when possible.
Give us a shout if we can help you with your NGINX setup.
Feature image by Special Collections Toronto Public Library licensed CC BY-SA 2.0.