The ultimate guide to choosing a Linux managed service provider
Welcome to the ultimate guide to choosing a Linux managed service provider.
As Dogsbody Technology Ltd celebrates its 10th birthday, we are incredibly grateful to our loyal and satisfied customers – many, who have been with us since the beginning.
Technology moves fast and over those years, we have continuously evolved our portfolio and we’re delighted so many of our customers have remained with us. We’d like to think that it’s not through apathy, it’s because they picked the right Linux managed service provider – us!
Reflecting on the first 10 years of our journey, we asked some of our customers how they chose us originally and what they’d look for in an MSP partner now. Our write up is below – we hope it helps you to come to the right decision.
Test whether they are impartial – will they give you the best advice for your business?

Managed service providers can be affiliated with specific services, meaning they receive referral payments from a provider when they sign up a new customer. They are therefore more likely to recommend and push technology which is right for them – but not necessarily right for you.
Here at Dogsbody Technology, our honest, “All of Market”, industry advice is exactly that. We recommend, based on your needs. We will help you to choose the most suitable environment for your business’s data. Our recommended solutions have ranged from a shared hosted server, to a VPS (Virtual Private Server), to a dedicated server or even an entire datacentre.
With a combined 50+ years of Linux experience (we really have seen it all), we’ll ensure you get the correct advice to safeguard and future proof your IT systems.
“Dogsbody’s communication is excellent and the team is very professional and friendly.
Since working with them, none of our clients’ websites have experienced any downtime and should there be an issue, they advise us very quickly and will recommend the best course of action.
We look forward to a long relationship with Dogsbody and would recommend them at every opportunity.”
Sam Bliss – Adapt Digital
Business needs change quickly, and technology changes even quicker. Make sure that you choose a Linux managed service provider which has the flexibility to take on your projects and services, as well as the ability to be that impartial guide to the future.
Find out how their support really works
Ongoing support is key when it comes to choosing a Linux managed service provider. Don’t be afraid to really get under the hood. Ask difficult questions and ensure you get references from existing customers – don’t necessarily rely on shiny brochureware.
Ask what contact methods you can use ? Check whether support is outsourced? Ask if they offer 24/7 support? Are you paying a premium for that – maybe you don’t need it?
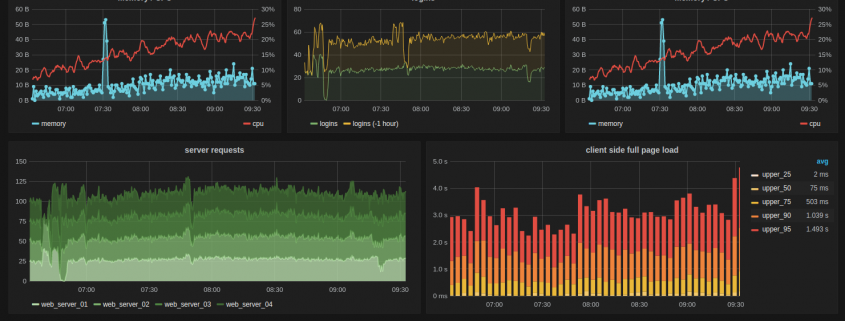
Here at Dogsbody Technology your calls aren’t answered by a virtual helpdesk. They means too much to us. Each customer gets a dedicated point of contact, we are solely UK-based and none of our support is outsourced, unless we agree with you that it’s the best option. We even offer support via Slack for our larger customers.
Check and check again, their security credentials

Security is all about risk and budget. Not all MSPs are as obsessed with security as we are.
Some questions to think about when evaluating a Linux MSP to work with:
- What clearance levels do your staff have?
- Where and how is your data kept?
- What certifications does the company have? ISO 9001 / ISO 27001
- How long have staff worked there?
- What policies do they have regarding data access and retention?
- How do they communicate when sharing sensitive information?
Dogsbody Technology offers custom maintenance plans – meaning if you don’t have it, need it or simply can’t afford it right now, you don’t pay for it!.
It’s not a one size fit all approach. Our starter plan includes:
- patching (automatic or manual)
- reputation alerts for IP addresses, SSL certificates and domains
- resource and port monitoring
It doesn’t have to end there. Custom plans means we can enhance your maintenance as you grow. Options include
- Annual, monthly, daily or hourly Penetration Testing of your infrastructure or application
- Exception tracking of system logs to spot errors for issues you don’t know you had
- MoD level intrusion detection of all files on your systems
- Backup testing – do you know your backups are actually working?!
- Real user monitoring (RUM testing) – monitor load time and your user experience.
- Password testing… and the list goes on.
We create maintenance plans to suit you, your business and your budget. We can also provide ad hoc maintenance, if this is what your business requires right now.
“Having been a customer of Dogsbody Technology for many years I have always been impressed at their high standards of ability, professionalism as well as patience with those of us who are not so technically minded!
I would not hesitate to recommend them.”
Jo Benton – Benton Evans Architects
Cheap isn’t necessarily best when it comes to managing your critical IT. We work hard to earn your trust and work even harder to keep it.
Do they make it easy for you to leave?

This is such a powerful question to ask a prospective Linux MSP partner.
It may sound negative asking this question during an evaluation phase, however we know that not all relationships work out longer term. Sometimes you just don’t know this until you’re well into a contract. Asking what hoops you have to jump through if the relationship doesn’t work, at the start of the process, is therefore a sensible question to ask.
Here at Dogsbody, all server builds come with a build guide – which our customers own – we won’t demand a ransom to hand them over. Not only is this good practice if you had to rebuild your server in a hurry, but it allows another partner to take over, if necessary.
Test their values
Here at Dogsbody, our ethos is on our website for all to see. Our customers, big and small, share this ethos.
Does the MSP you’re about to partner with share your ethos?
Do they return calls promptly?
Do they return emails promptly?
Are those emails well written? Are they spelt correctly? You can tell so much about a company from this simple test. If they don’t bother to check through an email before sending it over – what else aren’t they double checking?
Do they do the right thing? Do they talk about their charitable endeavours? Do they treat data right? Do they treat their employees right?
Don’t ignore a gut feeling. If you’re not sure about something or someone – check again. Don’t make an expensive mistake.
The most important question of all – do you trust them?

When partnering with an IT provider, you will likely be handing over the keys to your innermost secrets and most valuable assets, which is a scary thought. This doesn’t happen with any other provider. An accountant, a lawyer, a consultant marketer would never gain such important access.
Establishing trust therefore, is a huge part of your selection process and we know that you can’t do this overnight.
It’s hard to answer this question when you may have only met the key members of the team once and talked to them a few times. Much like hiring employees, choosing a Linux managed service provider is similar.
Meet them again, interview them, look at reviews and ask for references from customers they currently work with who are similar in size/scope to your business. Ultimately this is a gut decision … Do they feel like a trusted pair of hands? Is it all sounding too good to be true? Do they seem honest? And – do they seem to CARE?
Here at Dogsbody we always say we ‘feel our customers’ pain’.
If it’s hurting you, it’s hurting us.
We like it that way.
Looking for a Linux managed service provider? Contact our managed services team for a chat and get to know us.