
Exploring character encoding types
Morse code was first used to transfer information in the 1840’s. As you’re probably aware, it uses a series of dots and dashes to represent each character.
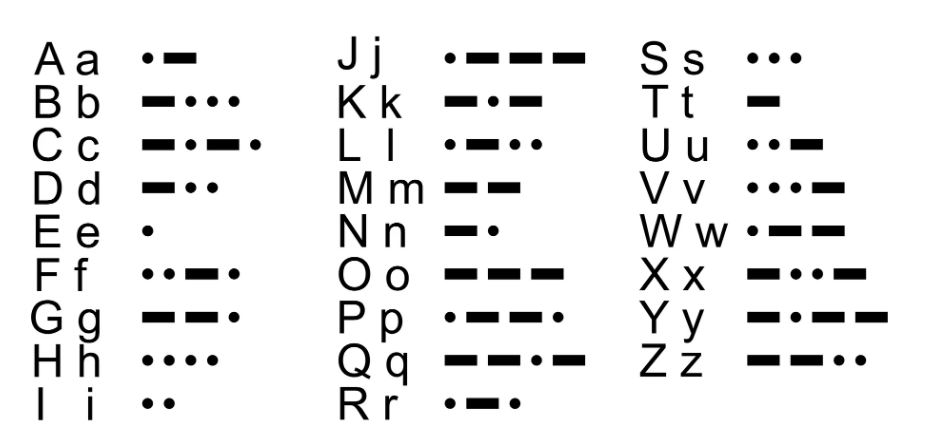
Computers need a way to represent characters in binary form – as a series of ones and zeros – equivalent to the dots and dashes used by Morse code.
ASCII
A widely used way for computers to encode information, is ASCII (American Standard Code for Information Interchange), created in the 1960’s.
ASCII defines a string of seven ones and zeros that represent the letters A-Z, upper and lowercase as well as numbers 0-9 and common symbols. 128 characters in total.
8 bit encoding
As you’d expect, ASCII is well suited for use in America, however it’s missing many characters that are frequently used in other countries.
For example, it doesn’t include characters like é or £ & €.
Due to ASCII’s popularity, it’s been used as a base to create many different encodings. All these different encodings add an extra eighth bit, doubling the possible number of characters and using the additional space for characters used by differing groups …
- Latin 1 – Adds Western Europe and Americas (Afrikaans, Danish, Dutch, Finnish, French, German, Icelandic, Irish, Italian, Norwegian, Spanish and Swedish) characters.
- Latin 2 – Adds Latin-written Slavic and Central European (Czech, Hungarian, Polish, Romanian, Croatian, Slovak, Slovene) characters.
- Latin 3 – Adds Esperanto, Galician, Maltese, and Turkish characters.
- Latin 4 – Adds Scandinavia/Baltic, Estonian, Latvian, and Lithuanian characters (is an incomplete predecessor of Latin 6).
- Cyrillic – Adds Bulgarian, Byelorussian, Macedonian, Russian, Serbian and Ukrainian characters.
- Arabic – Adds Non-accented Arabic characters.
- Modern Greek – Adds Greek characters.
- Hebrew – Adds Non-accented Hebrew characters.
- Latin 5 – Same as Latin 1 except for Turkish instead of Icelandic characters
- Latin 6 – Adds Lappish/Nordic/Eskimo languages. Adds the last Inuit (Greenlandic) and Sami (Lappish) letters that were missing in Latin 4 to cover the entire Nordic area characters.
- etc.
All of this still doesn’t give global coverage though! There’s also an issue due to the inability of using different encodings on a single document, should you ever need to use characters from different character sets.
We need an alternative …
Unicode
Unicode seeks to unify all the characters into one set.
This simplifies communication, as everyone can use a shared character set and doesn’t need to convert between them.
Unicode allows for over a million characters!
One of the most popular ways to encode Unicode, is as UTF-8. UTF-8 has a variable width. Depending on the character used to encode, either 8, 16, 24 or 32 bits are used.
For characters in the ASCII character set, only 8 bits need to be used.
Another way to encode Unicode is UTF-32, which always uses 32 bit. This fixed width is simpler, but causes it to often use significantly more space than UTF-8.
Emoji
You probably don’t need telling, but Emoji are picture characters.
For a long time, knowledge workers have created smiley faces and more complex emoticons using symbols.
To take this a step further, emoji provide a wealth of characters.
The data transferred is always the same, but the pictures used differ between different platforms. Depending on the device, you’re viewing this, our smiley face emoji, ?, will look different.
The popularity of emoji has actually helped push Unicode support, which includes emoji as part of its character set.
I’ve pulled out a few recently added ones and you can see more on the Unicode website.
U+1F996 added in 2017 – T-Rex ?
U+1F99C added in 2018 – Parrot ?
U+1F9A5 added in 2019 – Sloth ?
Feature image by Thomas licensed CC BY-SA 2.0.

Leave a Reply
Want to join the discussion?Feel free to contribute!